Charger des données via Pandas, en Python, pour les stocker dans une dataframe, préalablement à leur traitement, est une tâche récurrente en analyse de données.
Très souvent, les données sont stockées dans des fichiers csv pour compresser l’information.
Lorsque l’on ouvre un csv dans un éditeur de texte, on peut alors voir des lignes de données, subdivisées en colonnes par un séparateur, généralement une virgule. On peut alors voir, dans la toute première ligne du fichier, le nom des colonnes, aussi appelé header. Cependant, il arrive que des csv ne contiennent pas de header.
Dans ce cas, un risque est que, lors du chargement du csv dans une dataframe via la méthode pandas.read_csv, la première ligne de données soit lue comme un header alors que ce n’est qu’une ligne de données.
Il faut alors anticiper le fait que l’on ait pas de header et adapter la méthode de chargement de données.
🚩 Problème :
Comment charger un csv sans header dans une dataframe à l’aide de Pandas ?
✅ Solution :
Utiliser header=None dans la méthode pandas.read_csv. Pour charger un csv sans header du nom de test_data.csv dans une dataframe, faire :
import pandas as pd
file_name = "test_data.csv"
df = pd.read_csv(file_name, header=None)
🤠 Exemple :
Imaginons que l’on ait un csv du nom de test_data.csv, qui contienne les lignes suivantes :
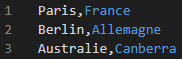
test_data.csvLa tentative naïve pour charger ces données dans une dataframe serait de faire :

La dataframe que l’on obtient sera alors :
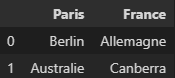
On note que le nom des colonnes n’est pas bon. (« Paris », « France ») devrait être une ligne de données et non le nom des colonnes. Pour le nom des colonnes, en fait on s’attendrait plutôt à (« Capitale », « Pays »).
Le problème est que Pandas interprète la première ligne du csv comme un header.
Une solution est alors de procéder comme suit :

On obtient alors une dataframe qui a plus de sens et où Pandas est parti du principe qu’il n’y avait pas de header dans le csv :
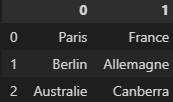
On voit que les noms de colonnes ont été par défaut mis à « 0 » et « 1 ». Ils pourront ensuite être changés, et peuvent même être précisés lors du chargement du csv.

Laisser un commentaire